
14 min read
Privacy Management mit PowerShell – hier kommen die wichtigsten Funktionen von Priva auf einen Blick
Kennst du Priva? Datenschutzmanagement, Datenschutzrichtlinien, Regeln und Subjektrechte-Anfragen (data subject rights...
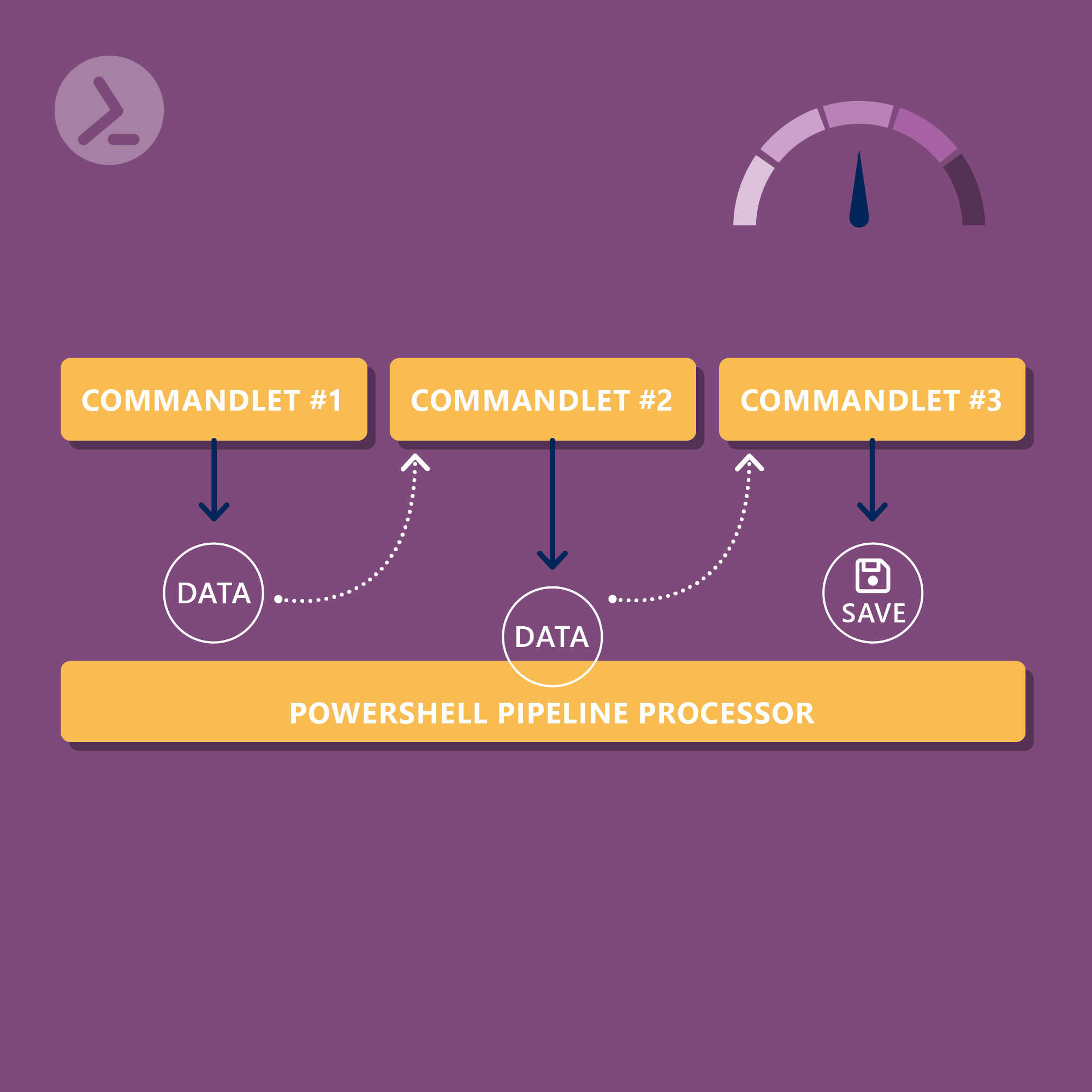
Mit der PowerShell Pipeline lässt es sich effizient arbeiten – in diesem Blogbeitrag steigt Philip Lorenz tiefer in das Thema ein.
Die Pipeline ist ein zentrales Konzept in PowerShell, das die Weitergabe von Ausgaben einer Funktion oder eines Cmdlets als Eingaben an eine andere ermöglicht. Dies schafft eine flexible und effiziente Methode zur Verarbeitung von Daten, indem einzelne, gut definierte Aufgaben verkettet werden können. Das Prinzip "one at a time" ermöglicht es, ressourcenschonend auch große Datenmengen zu verarbeiten. Im Artikel "Effizientes Arbeiten mit der PowerShell-Pipeline: Ein Leitfaden für Administratoren" habe ich dir bereits gezeigt, wie du die Pipeline zum Verketten bereits bestehender Cmdlets nutzen kann. In diesem Blogbeitrag zeige ich dir, wie du deine eigenen Funktionen Pipeline-ready machst!
Die Integration des Pipeline-Supports in eigenen Funktionen ist nicht nur eine gute Praxis, sondern erweitert auch die Funktionalität und die Wiederverwendbarkeit des Codes. Die Bereitstellung von Pipeline-Support in eigenen Funktionen erfordert ein Verständnis der Pipeline-Mechanismen und die Anwendung geeigneter Parameter- und Verarbeitungstechniken. Im Verlauf dieses Artikels werden wir diese Konzepte anhand von rudimentären bis hin zu fortgeschrittenen Funktionen erläutern und verdeutlichen, wie du die Pipeline-Effizienz in deinen Skripten maximieren kannst.
Um die Pipeline in PowerShell effektiv nutzen zu können, ist es wichtig, einige Grundlagen zu verstehen. Zwei zentrale Elemente sind hier das Filter-Keyword und die spezielle Variable $_. Sie spielen eine entscheidende Rolle, wenn es darum geht, eine einfache Funktion zu erstellen, die Pipeline-Support bietet.
Das Filter-Keyword in PowerShell ermöglicht es, eine Art von Funktion zu erstellen, die speziell für die Verarbeitung von Pipeline-Eingaben ausgelegt ist. Ein Filter nimmt Input aus der Pipeline, verarbeitet diesen und gibt etwas zurück an die Pipeline. Die $_ Variable repräsentiert das aktuelle Objekt in der Pipeline, das verarbeitet wird. Hier ist eine einfache Funktion, die zeigt, wie das Filter-Keyword und die $_ Variable verwendet werden können:
Filter Convert-ToUpperCase {
Write-Output "Input in uppercase: $($_.ToUpper())"
}
In diesem Beispiel haben wir einen Filter namens Convert-ToUpperCase erstellt. Dieser Filter nimmt Texteinträge aus der Pipeline, und für jeden Eintrag wird die Methode ToUpper aufgerufen, um den Text in Großbuchstaben umzuwandeln. Es findet außerdem direkt eine Ausgabe auf der Konsole statt. Wenn du diesen Filter in einer Pipeline verwendest, wird jeder Texteintrag einzeln verarbeitet in Großbuchstaben and die Ausgabe weitergeleitet:
"hello", "world" | Convert-ToUpperCase
Die Ausgabe wäre:
Input in uppercase: HELLO
Input in uppercase: WORLD
Die Verwendung von Filter und $_ ist eine einfache und effektive Methode, um Pipeline-Support in deine Funktionen zu integrieren. Es ermöglicht eine klare und leicht verständliche Art, Objekte aus der Pipeline zu nehmen, zu verarbeiten und weiterzuleiten, was die Grundlage für komplexere Funktionen und Pipeline-Operationen bildet.
Im nächsten Abschnitt werden wir uns mit den sogenannten Named Parameters befassen und eine erweiterte Funktion erstellen, die über den Rahmen einer einfachen Funktion hinausgeht und weitere Möglichkeiten zur Interaktion mit der Pipeline bietet.
Während einfache Funktionen und Filter für viele Aufgaben ausreichend sind, ermöglichen erweiterte Funktionen in PowerShell eine größere Kontrolle und Flexibilität, insbesondere wenn es um die Arbeit mit Pipelines geht. Einer der Schlüssel zu dieser erweiterten Funktionalität sind Named Parameters.
Named Parameters erlauben es uns, die Eingabe von Daten in einer strukturierten und verständlichen Weise zu steuern. Sie können nicht nur Typen für die Eingabeparameter festlegen, sondern auch Standardwerte definieren und Validierungen hinzufügen.
Hier ist ein Beispiel für eine erweiterte Funktion mit Named Parameters:
function Get-ModifiedFiles {
param (
[Parameter(Mandatory=$true, ValueFromPipeline=$true)]
[string]$Path,
[datetime]$Since
)
process {
$files = Get-ChildItem -Path
$Path -Recurse |
Where-Object { $_.LastWriteTime -gt $Since }
$files
}
}
In dieser Funktion Get-ModifiedFiles haben wir zwei Named Parameters definiert: $Path und $Since. Der Parameter $Path ist obligatorisch und akzeptiert Eingaben aus der Pipeline, während $Since optional ist. Im process-Block verwenden wir Get-ChildItem, um alle Dateien im angegebenen Pfad zu ermitteln, und Where-Object, um die Dateien zu filtern, die nach dem angegebenen Datum geändert wurden.
Hier ist ein Beispielaufruf:
"./" | Get-ModifiedFiles -Since (Get-Date).AddDays(-7)
Ausgabe:
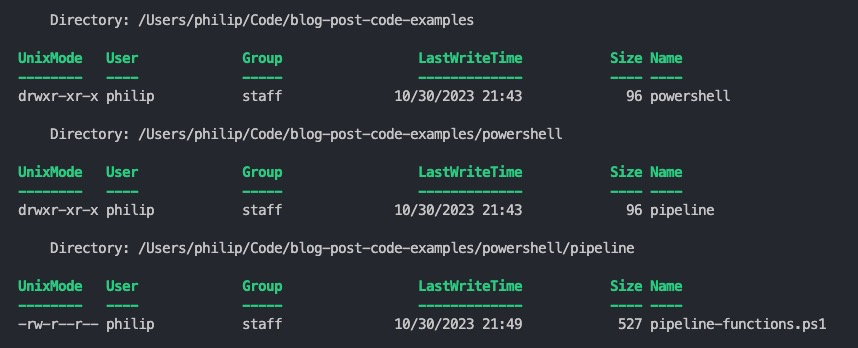
In diesem Aufruf wird das aktuelle Verzeichnis als einfacher String an die Funktion Get-ModifiedFiles übergeben, und es werden alle Dateien zurückgegeben, die in den letzten sieben Tagen geändert wurden.
Named Parameters bieten eine klare und explizite Möglichkeit zur Steuerung der Funktionseingaben und ermöglichen eine feinere Kontrolle über die Datenverarbeitung innerhalb der Funktion.
Im nächsten Kapitel werden wir die Strukturierung von Funktionen mit Begin, Process, End und Clean Blöcken betrachten.
Die Strukturierung von Funktionen mit den Blöcken Begin, Process, End und dem neu eingeführten Clean-Block in PowerShell 7.3 bietet eine robuste Methode zur Verarbeitung von Pipeline-Daten und zur Ressourcenbereinigung. Diese Blöcke ermöglichen es, Code in logische Segmente zu unterteilen, die zu unterschiedlichen Zeitpunkten während der Ausführung der Funktion aufgerufen werden.
Der Clean Block, eingeführt in PowerShell 7.3, bietet eine Möglichkeit zur Bereinigung von Ressourcen, die sich über die Begin, Process und End Blöcke erstrecken. Semantisch ähnelt er einem Finally Block und deckt alle anderen benannten Blöcke einer Funktion ab. Die Ressourcenbereinigung wird in verschiedenen Szenarien erzwungen, beispielsweise wenn die Pipelineausführung normal abgeschlossen wird, durch einen Abbruchfehler unterbrochen wird, oder durch Select-Object -First angehalten oder durch STRG+C oder StopProcessing() beendet wird.
Hier ein Beispiel, das die Verwendung aller Blöcke demonstriert:
function Get-Size {
param (
[Parameter(Mandatory=$true, ValueFromPipeline=$true)]
[string]$Path
)
begin {
# Initializing variables
$totalSize = 0
$tempDirectory = "./tmp"
# Initialization: Creating temporary directory
if (-not (Test-Path $tempDirectory)) {
New-Item -Path $tempDirectory -ItemType Directory | Out-Null
}
}
process {
# Checking if the path exists and is a file
if (Test-Path $Path -PathType Leaf) {
$fileInfo = Get-Item $Path
$fileSize = $fileInfo.Length
$totalSize += $fileSize
# Writing file information to a temporary file
$outputPath = Join-Path $tempDirectory ($fileInfo.Name + ".txt")
$fileInfo | Out-File $outputPath
}
}
end {
# Outputting the total size of all processed files
Write-Output "Total size of all processed files: $($totalSize / 1MB) MB"
}
clean {
# Deleting temporary directory
Remove-Item $tempDirectory -Recurse -Force
}
}
Führt man folgenden Code aus:
$files = @()
$files += "/Users/philip/Code/blog-post-code-examples/blog.docx"
$files += "/Users/philip/Code/blog-post-code-examples/image.dmg"
$files | Get-Size
Erhält man die folgende Ausgabe:
Total size of all processed files: 615.562695503235 MB
Durch die Verwendung von Begin, Process, End und Clean Blöcken wird die Funktion strukturiert und ermöglicht eine effiziente Verarbeitung und Bereinigung.
Bisher haben wir uns mit der Übergabe von Werten ByValue an Funktionen beschäftigt. PowerShell bietet jedoch auch die Möglichkeit, Werte ByPropertyName zu übergeben. Dies ermöglicht eine flexiblere und intuitive Interaktion mit Funktionen.
Hier ist ein Beispiel, um die Implementierung von ByPropertyName zu demonstrieren:
function Get-FileDetail {
param (
[Parameter(ValueFromPipelineByPropertyName=$true)]
[string]$FullName
)
process {
$fileInfo = Get-Item $FullName
$fileDetail = @{
Name = $fileInfo.Name
Size = $fileInfo.Length
LastModified = $fileInfo.LastWriteTime
}
$fileDetail
}
}
Get-ChildItem -Path "./" | Get-FileDetail
Folgendes wird in der Konsole ausgegeben:
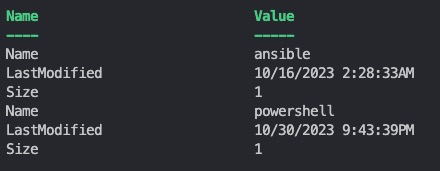
In der Funktion Get-FileDetail haben wir den Parameter $FullName mit dem Attribut ValueFromPipelineByPropertyName=$true definiert. Dies ermöglicht es, dass die Funktion Werte aus der Pipeline akzeptiert, die auf der Grundlage des Namens des Parameters $FullName zugeordnet sind. Im Beispielaufruf wird die Ausgabe von Get-ChildItem an Get-FileDetail weitergeleitet, wobei die FullName-Eigenschaft der Ausgabeobjekte von Get-ChildItem dem Parameter $FileName von Get-FileDetail zugeordnet wird.
Durch die Verwendung von ByPropertyName können Funktionen intuitiver und flexibler in Pipelines eingesetzt werden, und die Zuordnung von Eingabewerten zu Funktionen wird transparenter.
Im nächsten Absatz werden wir die automatische Variable $Input betrachten, die eine weitere Möglichkeit zur Verarbeitung von Pipeline-Eingaben bietet, insbesondere wenn der Input als Block und nicht als einzelne Items behandelt werden soll.
Während viele PowerShell-Entwickler mit der Pipeline-Variable $_ vertraut sind, ist $Input weniger bekannt, bietet aber in bestimmten Szenarien wertvolle Funktionen.
Die Variable $Input ermöglicht es, die gesamte Pipeline-Eingabe als Enumerator zu behandeln. Das bedeutet, dass man, statt jedes einzelne Element der Pipeline nacheinander zu verarbeiten, auf die gesamte Eingabe als Ganzes zugreifen kann. Dies kann in Szenarien nützlich sein, in denen man die Eingabe als Block behandeln möchte, z. B. beim Sortieren oder Gruppieren von Daten.
Es ist wichtig zu beachten, dass $Input ein Enumerator ist und nicht direkt als Array verwendet werden kann. Um $Input als ein echtes Array zu verwenden, kann man es in @() einschließen.
Hier ist ein einfaches Beispiel:
function Sort-InputData {
process {
$dataArray = @($Input)
$sortedData = $dataArray | Sort-Object
$sortedData
}
}
# Beispielaufruf
1, 5, 3, 4, 2 | Sort-InputData
In dieser Funktion Soft-InputData sammeln wir zuerst alle Pipeline-Eingaben in einem Array $dataArray und sortieren dann diese Daten. Das Ergebnis ist eine sortierte Liste der Zahlen.
Die Verwendung von $Input ist besonders nützlich, wenn man mehrere Operationen auf der gesamten Pipeline-Eingabe durchführen möchte, ohne jeden Wert einzeln zu verarbeiten. Es ist jedoch wichtig, den Unterschied zwischen $Input und $_ zu verstehen und die richtige Variable für das jeweilige Szenario auszuwählen.
PowerShell-Pipelines stellen zweifellos eines der wichtigsten Merkmale der PowerShell dar. Ihre Fähigkeit, Daten effizient und nahtlos zwischen verschiedenen Cmdlets und Funktionen zu übertragen, hebt sie von anderen Skriptsprachen ab. Für jeden IT-Profi, der bestrebt ist, komplexe Aufgaben zu automatisieren und Workflows zu optimieren, sind sie ein unverzichtbares Werkzeug.

Entfalte das volle Potential von PowerShell mit unserem praktischen Poster. Egal ob Anfänger oder erfahrener Profi, dieses Cheat Sheet ist darauf ausgelegt, dein Anlaufpunkt für die wichtigsten und am häufigsten verwendeten Cmdlets zu sein.
Das Poster gibt es zum Download und in Papierform.

Jul 16, 2024 by Damian Scoles
Kennst du Priva? Datenschutzmanagement, Datenschutzrichtlinien, Regeln und Subjektrechte-Anfragen (data subject rights...
Jul 3, 2024 by Matthias Jütte
Jeden letzten Freitag im Juli wird der System Administrator Appreciation Day gefeiert, einen besonderen Tag, der den...
Jun 28, 2024 by Philip Lorenz
Windows PowerShell 5.1 ist in der Regel vorinstalliert und der Standard – lohnt sich ein Wechsel auf PowerShell 7, oder...
Philip Lorenz ist als DevOps- und Cloud-Engineer tätig. Neben dieser Tätigkeit hält er Schulungen und erstellt Lerninhalte rund um die Themen PowerShell, Automatisierung und Cloud-Computing.
